

Building a Midjourney Clone for Muslims - Side Project Overview
1/2024 Aman Azad

New year, new side project.
Video Overview
Contents
- Product Overview
- AI: Generating Embeddings + RAG + LLM + Costs
- Database Choice: Postgres + pgvector
- API: Generating Responses
- Discord Bot
- Infrastructure - AWS via SST (+ OpenNext)
- Expected Learnings and Time Frame
2023 saw me spending lots of time on Muslim Twitter amidst endless debates on the meaning of ahadith, ayats from the Quran, lay people trying to make sense of a 1400 year old legal tradition that is Shariah, so on, and so on. All of this reaching a height as Israel continues its assault on the people of Gaza.
Of course also being in tech, my feed was also filled with tons of indie-hackers building out little AI products/GPT-wrappers like Damon Chen’s pdf.ai and Danny Postma’s headshotpro.com.
In a classic software engineer fashion, I wanted to see if there was a problem for my solution of AI tech.
What I came up with was something that I’m sure would’ve felt magical to Imam Al Ghazali in 12th century Baghdad - what if there was a way to semantically search across the entire corpus of Islamic religious texts, comprised of the 6,236 ayats (verses) of the Quran, as well as the roughly ~38,000 ahadith (sayings) of our Prophet Muhammad (ﷺ, peace be upon him) as recorded in the 6 major books of hadith?
Can I build this tool using off-the-shelf AI products like OpenAI, and publicly available datasets? Will this actually be useful, or compelling for the Muslim ummah to use?
The answer to all of these is either a resounding “yes”, or “worth a shot”, hence why I’m deciding to build it. Here’s the tech spec doc scoping out the nuts and bolts of how I plan to build this. I’ll end with what I hope the learnings are from doing this project.
Product Overview

We’re going to bite Midjourney hard on this project.
This’ll be a Discord bot that exposes a single slash command “/askdeen”. This command will let users enter a prompt, and return back the most relevant pieces of text from the Quran, Hadith, and Islamic History (via Wikipedia). This will be a paid bot, and will ask users to subscribe for $5/mo.
We should have a simple web app that shows the user all of their generated question-answer pairs, and some place to manage their subscription.
This is an example response I hope to get out the product at the end of this.
If we prompt the bot with the following:
“/askdeen What is the importance of salat (prayer)?”
I expect to see something like the following:
[Quran]
حَـٰفِظُوا۟ عَلَى ٱلصَّلَوَٰتِ وَٱلصَّلَوٰةِ ٱلْوُسْطَىٰ وَقُومُوا۟ لِلَّهِ قَـٰنِتِينَ
Observe the five obligatory prayers—especially the middle prayer—and stand in true devotion to Allah.
Quran, 2:238
قَدْ أَفْلَحَ ٱلْمُؤْمِنُونَ
ٱلَّذِينَ هُمْ فِى صَلَاتِهِمْ خَـٰشِعُونَ
Successful indeed are the believers:
those who humble themselves in prayer;
Quran, 23:1-2
[Hadith]
Abdullah bin Umar said, "Allah's Messenger (ﷺ) entered the Ka'ba along with Usama bin Zaid, Bilal and Uthman bin Talha Al-Hajabi and closed the door and stayed there for some time. I asked Bilal when he came out, 'What did the Prophet (ﷺ) do?' He replied, 'He offered prayer with one pillar to his left and one to his right and three behind.' In those days the Ka'ba was supported by six pillars." Malik said: "There were two pillars on his (the Prophet's) right side."
Sahih al-Bukhari 505
Yunus (a narrator) said: I think he narrated it (the tradition) from the Prophet (ﷺ):) The first thing about which the people will be called to account out of their actions on the Day of Judgment is prayer. Our Lord, the Exalted, will say to the angels - though He knows better: Look into the prayer of My servant and see whether he has offered it perfectly or imperfectly. If it is perfect, that will be recorded perfect.
If it is defective, He will say: See there are some optional prayers offered by My servant. If there are optional prayer to his credit, He will say: Compensate the obligatory prayer by the optional prayer for My servant. Then all the actions will be considered similarly
Sunan Abi Dawud 864
[Tafsir]
The provided Quranic verses emphasize the need for strict observance of Salat, especially the Middle Prayer, and highlight that success is granted to believers who perform their prayers with solemnity and full submissiveness. The accompanying Hadiths stress the cleansing and expiating nature of the five daily prayers, equating them to a purification similar to bathing in a river five times a day. Additionally, the Hadith from Sahih Muslim underscores the pivotal role of prayer in one's accountability on the Day of Judgment, emphasizing its priority among all deeds. Overall, these teachings underscore the central role of Salat in the life of a devout Muslim, not only as a ritual but as a means of spiritual purification and accountability in the Hereafter.
Caution: Please consult a trusted Imam with the source content provided.
As I develop this, I'm sure there'll be some key features I'll want to add in. Off the top of my head, things like "seeing more results from the Quran" or hadith, or retrieving more analysis. Punting these until after we have a version 1 finished and released.
Let’s dive into the nuts and bolts of how we’re going to get this done, starting with the data/AI bits first, then going over the choice of database, the API we’ll use to request generations, and lastly how we’ll set up the Discord bot.
AI: Generating Embeddings + RAG + LLM + Costs
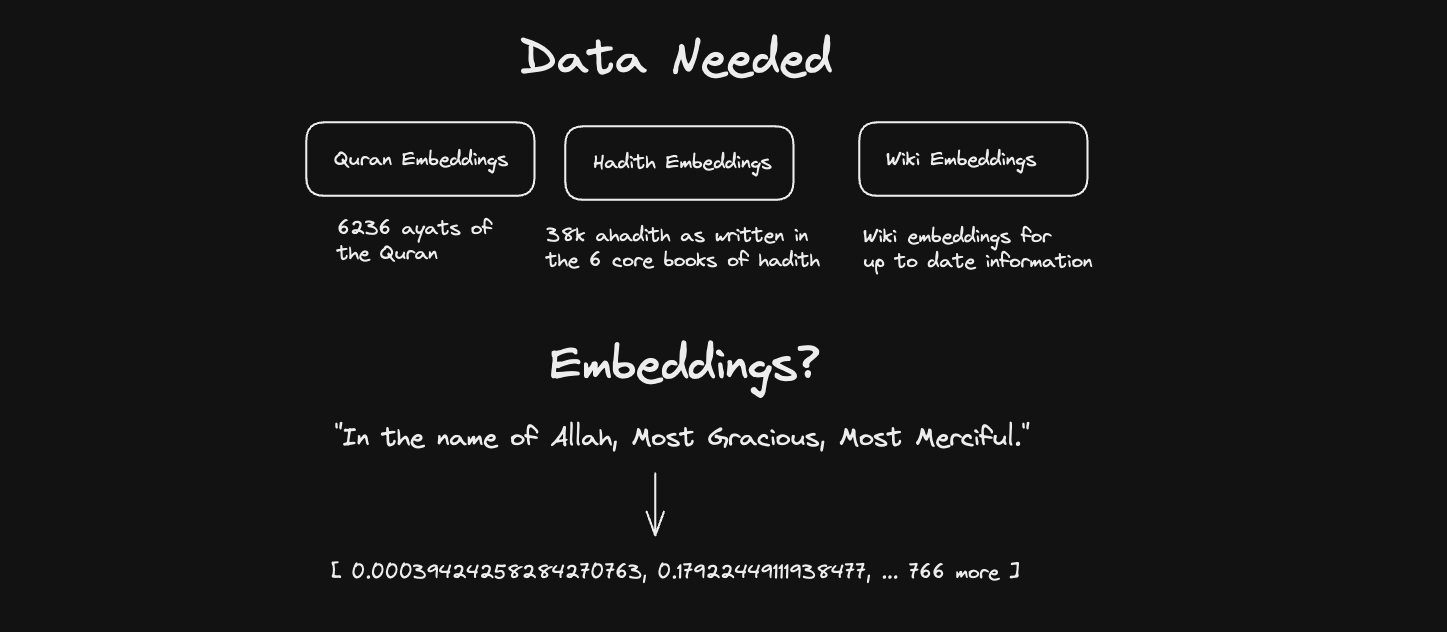
Semantic searches over a large corpus of data means implementing some RAG (retrieval augmented generation) solution.
What we’ll want to do is generate embeddings of all the text content we want searched over. What’s an embedding? Essentially it’s a vector representation of some text content. So we can take a particular string of text, ie a verse from the Quran, and translate into an array of 768 numbers. The 768 in this case refers to the number of dimensions in our embeddings vector.
How this is done, no clue! But OpenAI has an endpoint that’ll generate these for us so I’m content to let Altman the rest of the OpenAI team figure that out.
What we can do with embeddings is take in user prompts, generate embeddings for it using the same OpenAI API, then mathematically compare the nearness of the input prompt to our data. This unlocks the semantic search we’re looking for. See cosine similarity or K nearest neighbors for more info on how this is mathematically done.
What we’ll want to have is embeddings for all 6,236 ayats of the Quran, all 38,000 hadith, and embeddings for Wikipedia to make sure our responses have appropriate historical context.
Luckily, there are public datasets available which make this job infinitely easier.
Here is a dataset with embeddings for every single ayat in the Quran already generated. We’ll need to do some work here to add in the original Arabic as written in the Quran. To do so, we’ll need do some simple ETL work to add in the absolute Ayat number. The absolute ayat number will reference the correct Arabic as listed in another publicly available source.
Here is a dataset of 38,000 ahadith. I’ll be extending this to include a column to contain the results from OpenAI’s embeddings API. We’ll release this on hugging face to make it publicly available afterwards.
Lastly our Wikipedia embeddings are also publicly available.
So the only real embeddings we’ll need to generate are for the 38k or so rows of ahadith. Besides OpenAI, there is the Cohere AI API for generating embeddings as well. Both are priced the same @ $0.10 per 1mill tokens. Best to go with the biggest name in the market.
The costs themselves aren’t crazy, some very rough back-of-napkin calculations gives us the following:
- Hadith is roughly 4.3mill tokens (~50 words per hadith * 4 tokens per word * 38k rows)
- 4.3mill tokens / 1mill tokens * $0.10 = ~$0.4
Database Choice: Postgres + pgvector
We’ll need to store all this data into a database of our own.
Our database solution needs to tick a few boxes:
- Storing high-dimensionality data (our 768 dimension embeddings)
- Querying for embedding similarity
- I’ll also want to leverage something in the AWS ecosystem as I’ll be deploying the app with SST.
Postgres is a great choice here. Personally, I’ve been developing on Postgres for a long time and have a better understanding of how things work here for the rest of the non-AI related stuff (user bookkeeping, other endpoints we might need, etc). Postgres also has an extension called pgvector which supports the two use cases we need. We’ll be able to query directly against an input embedding to retrieve the most similar rows, with optionality as to which search algorithm we can use (cosine similarity, L2 distance, etc).
Postgres with pgvector also is now supported by AWS RDS, so this also will work nicely when we develop our infrastructure stack with SST.
API: Generating Responses
Again we’ll be using SST to deploy our API. We’ll build on top of AWS Lambda.
We’ll want some other endpoints to take care of the monetization layer, and some for other user housekeeping/boilerplate web app-y stuff, but those aren’t as important to the core value-add. I will most likely create a simple NextJS frontend to build the marketing/web app.
Let’s focus on the one endpoint for retrieving the user’s prompts and returning our AI responses.
Before we generate the corresponding embedding, we’ll verify if the user is a paid subscriber.
If we pass this check, we’ll go ahead and generate an embedding for the given prompt using OpenAI’s API.
We’ll then call a stored Postgres procedure to run a similarity check against our database to retrieve the most relevant responses. We’ll run a query against each dataset (Quran, Hadith, Wikipedia) represented as tables to get the following mix of data back:
- 2 ayat from the Quran
- 2 ahadith
- 1 wikipedia entry
We’ll then feed all of this into an additional prompt, along with the user’s original prompt and some instructions in order to generate a short paragraph analyzing all our retrieved text. We’ll do this by calling OpenAI’s general GPT-4 model.
The returned response will be all the source content, our short analysis, and a general disclaimer to caution users to seek the counsel of a trusted imam before making drastic changes to their lives.
Discord Bot
Once we’ve set up all the above, the discord bot becomes very straightforward to setup.
We’ll expose a single slash command “/askdeen” which will take in the prompt, and call the endpoint we exposed above.
Important note on usability, we’ll want to stream in the content by continuously re-editing the generated Discord message with a status update. Midjourney does this with their "%" complete message that shows up while the image is being generated.
We’ll also use Discord as our sole auth provider, and use it to generate user accounts for our Stripe integration for subscriptions.
Infrastructure - AWS via SST (+ OpenNext)
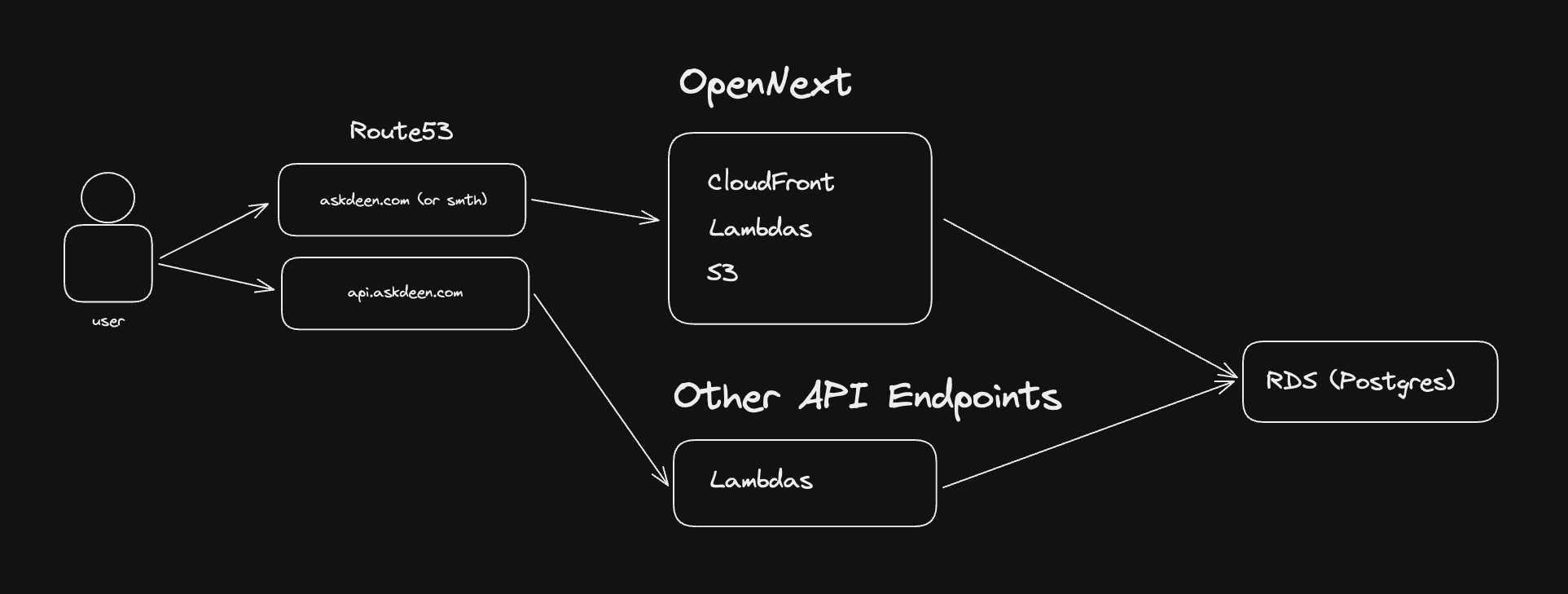
So now that we've mapped out what we want built, here's how I'll go about building it.
Like I said I'll be leveraging SST. The reason here is I'd like to get some hands on experience with some newer tech, namely OpenNext, AWS CDK (Cloud Development Kit), and the SST development experience itself.
Here's how I imagine all the building blocks coming together:
- OpenNext for our frontend, deployed auto-magically to a combination of AWS S3, CloudFront, and AWS Lambda (I'm assuming, we'll see!)
- Route53 to handle DNS of our eventual custom domain to the OpenNext entry URL (should be a CloudFront URL)
- AWS RDS via AWS Aurora to host our Postgres with the pgvector extension, called their serverless offering
- AWS Lambdas for our API endpoints
Nothing is clear until I get into development, but assuming this is mostly correct.
Expected Learnings and Time Frame

Out of this project comes a few tangible things under my belt:
- Knowledge of how SST works (AWS CDK, OpenNext, general developer experience)
- Knowledge of how to build a general AI/RAG/LLM solution
- A deeper appreciation for how Midjourney was built, plus any business learnings running a similar Discord product
- Any revenue resulting from the project itself
- Sadaqah Jariyah - a longer term communal benefit to the Muslims, and personal spiritual joy in building something for my community that can outlive me
I’m hoping to time box to a quarter, plus or minus a few weeks. Much of the hard work would have been in sourcing the text content for the ahadith, but Hugging Face has made that much simpler. Majority of the work I expect to be in response fine-tuning, playing around with the OpenAI API’s to make sure responses are actually useful. The Discord and Stripe integration I don’t believe will be too difficult, and any problems that do come up I expect to be well trodden with lots of Stack Overflow support.
As a personal rule, I have to scope out the objectives of my side projects before I jump into them.
Embarking on projects solo means I am at the whims of my own personal motivations and fancies. It is so easy to get off track and jump down rabbit holes, only to look back in 6 months having achieved nothing of note.
I think a lot of this gets washed over in the cult of Silicon Valley where it’s OK to fail well into your 40s, because you might not realize a cache of diamonds at the end of the tunnel your digging.

POV you just raised venture capital
Personally, I need to see value right away. Spending 3 years of my life chasing the VC-backed startup dream made me realize that path ended in meaningful financial and lifestyle changes for only a very, very small minority.